🔀
Transfer
Learning
Học chuyển giao trong Computer Vision — từ Feature Extraction đến Foundation Models và kỷ nguyên 2025+.
01 — Bản chất cốt lõi
Tái sử dụng
tri thức
đã học.
Trong ML truyền thống, training data và test data phải cùng phân phối — một giả định hiếm khi thỏa mãn trong thực tế. Transfer Learning phá vỡ rào cản này bằng cách tái dùng weights từ một bài toán nguồn quy mô lớn (ImageNet: 1.2M ảnh, 1000 lớp) để giải quyết bài toán đích có dữ liệu hạn chế.
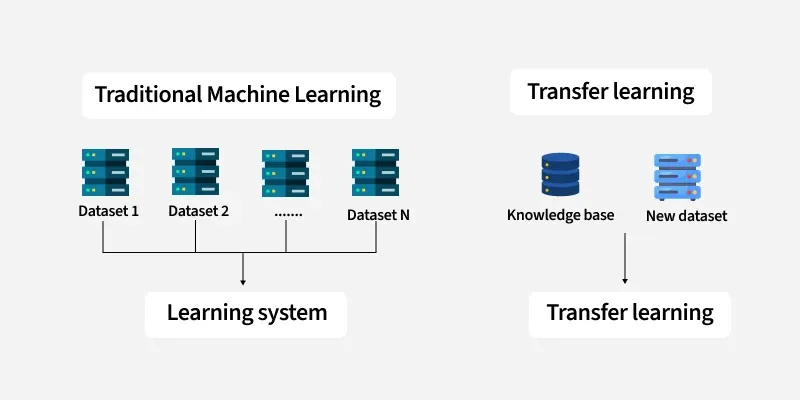
Truyền thống: N datasets độc lập → Transfer: Knowledge base tái sử dụng
01.2 — Hai chiến lược triển khai
Feature Extraction vs Fine-tuning
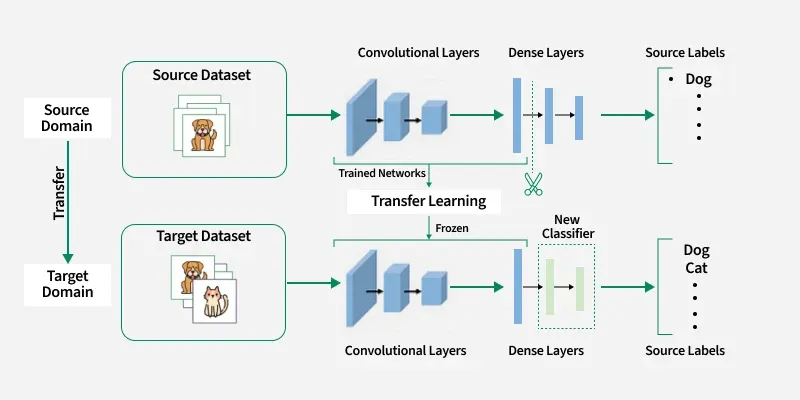
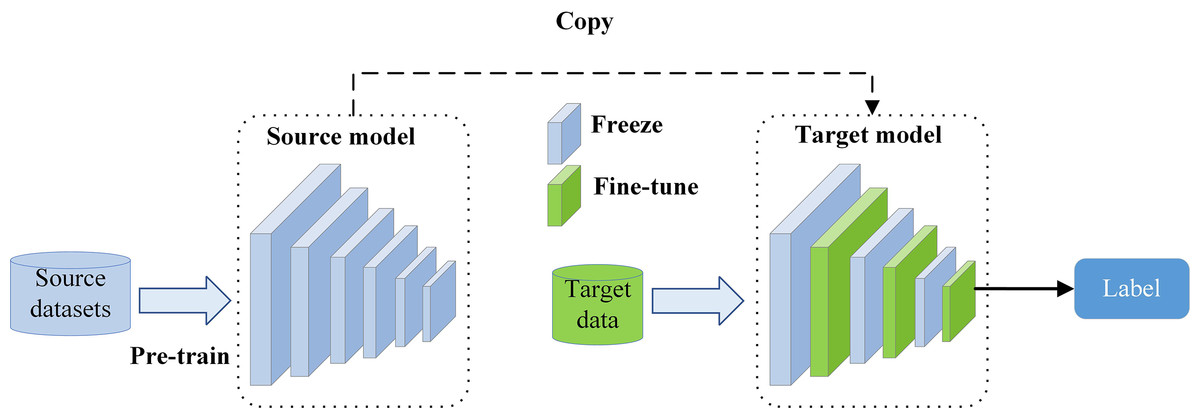
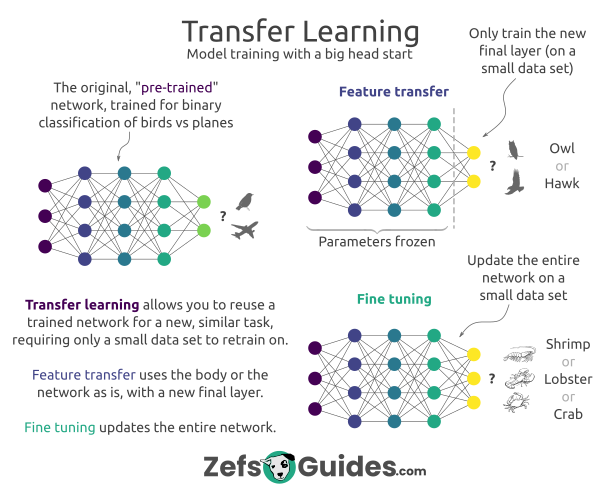
01.3 — Ma trận quyết định
Chọn chiến lược đúng dựa trên 2 trục.
Hai trục chính: Dataset Size (kích thước dữ liệu đích) và Domain Similarity (độ tương đồng giữa miền nguồn và đích). Đánh giá domain bằng LEEP hoặc LogME trước khi training.
Data lớn · Domain cao
Full Fine-tuning
Đủ data điều chỉnh mọi param không sợ memorize noise. LR nhỏ, đẩy tới SOTA.
Data lớn · Domain thấp
Fine-tune sâu / Train lại
Weights ImageNet chỉ là điểm khởi tạo tốt. Unfreeze toàn bộ hoặc train scratch.
Data nhỏ · Domain cao
Feature Extraction
Domain tương đồng → features bậc cao vẫn dùng được. Chỉ train linear head.
Data nhỏ · Domain thấp
Partial Fine-tune + Regularize
Freeze lớp nông, unfreeze vài lớp sâu. Áp dụng Dropout, Weight Decay nghiêm ngặt.
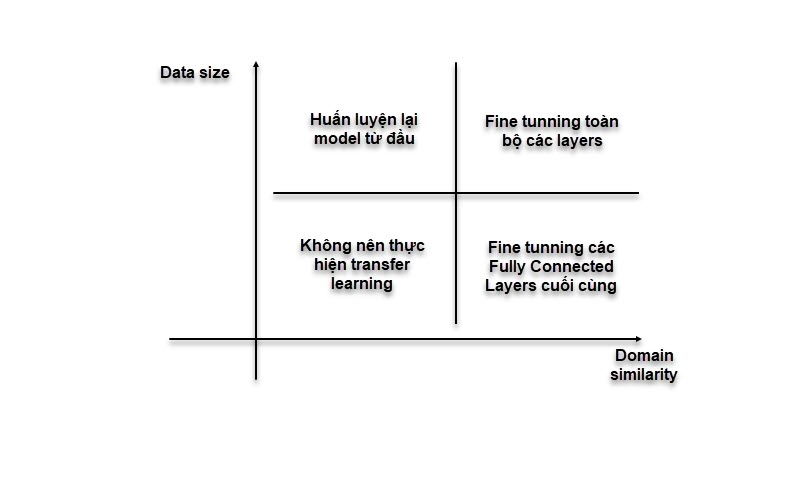
Sai chiến lược = lãng phí GPU và overfit. Dùng LEEP (Log Expected Empirical Prediction) hoặc LogME để đo transferability mà không cần train thử.
02 — Backbone Architectures
CNNs vs Vision Transformers
CONVOLUTIONAL NEURAL NETWORKS — Inductive bias mạnh, hiệu quả trên data nhỏ
ResNet-50
Skip connections giải quyết vanishing gradient. Baseline ổn định cho mọi tác vụ. Tốt trong chẩn đoán y tế, trích xuất đặc trưng cục bộ.
EfficientNetV2
Compound scaling đồng đều depth + width + resolution (NAS). Fused-MBConv tăng tốc train. Balance acc/VRAM/latency tốt nhất cho dataset nhỏ-vừa.
ConvNeXt
CNN hiện đại hoá theo ViT: GELU, LayerNorm, large-kernel depthwise, patchify stem. Duy trì inductive bias + đạt acc ngang Swin ở cùng budget.
VISION TRANSFORMERS — Global self-attention, tổng quát hóa cao
ViT (standard)
Chia ảnh thành patches 16×16, xử lý qua transformer. Self-Attention toàn cục từ lớp đầu. Cần pre-train lớn (JFT-300M), nhưng features khi TL rất flexible, shape bias cao.
Swin Transformer
Shifted window attention: tính attention trong cửa sổ cục bộ, dịch chuyển ranh giới giữa các lớp. Hierarchical feature maps, độ phức tạp tuyến tính. Lý tưởng cho detection/segmentation.
03.1 — Chuẩn bị dữ liệu
Preprocessing & Augmentation
📐 Data Preprocessing
Resizing & Cropping
Resize về 224×224 hoặc 384×384. Giữ aspect ratio tự nhiên, tránh biến dạng đối tượng chính.
Normalization — BẮTBUỘC
Phải normalize theo thống kê ImageNet: Mean=[0.485,0.456,0.406] và Std=[0.229,0.224,0.225]. Bỏ qua → distribution shift ngay tại lớp đầu vào.
🎲 Data Augmentation Nâng cao
MixUp
Nội suy tuyến tính 2 ảnh + nhãn one-hot. Decision boundaries mượt hơn, giảm overconfidence.
CutMix
Cắt patch từ ảnh này dán lên ảnh kia, nhãn mix theo diện tích. Ép model phân tích toàn cấu trúc, không chỉ 1 vùng.
RandAugment
Chọn ngẫu nhiên chuỗi transform với cường độ định sẵn. Đặc biệt tốt với ViTs cần data đa dạng.
03.2 – 03.3 — Freezing · BN · Learning Rate
Quy trình Fine-tuning an toàn
1️⃣ Gradual Unfreezing
Giai đoạn 1 — Warmup Head
Freeze toàn bộ backbone. Train classifier mới 1-2 epochs để weights ngẫu nhiên hội tụ về trạng thái ổn định.
Giai đoạn 2 — Top-Down Unfreeze
Loss ổn định → unfreeze dần từ lớp sâu nhất lên. Lớp sâu chứa task-specific features, lớp nông chỉ cần cạnh/màu sắc chung.
⚠️ Batch Normalization Trap
BN ở training mode liên tục cập nhật running_mean / running_var. Nếu data đích phân phối khác → statistics sai lệch → phá vỡ cân bằng gamma/beta ImageNet.
FIX: Ép BN layers ở eval() mode
for m in model.modules():
if isinstance(m, BN):
m.eval()📈 Learning Rate Strategy
Differential LR (phân tầng)
1e-3 → 1e-41e-51e-6Cosine Annealing + Linear Warmup
Warmup: tăng LR từ ~0 tuyến tính trong 10% steps đầu → tránh "gradient shock". Cosine decay: giảm mượt, tránh local minima, hội tụ tối ưu.
04 — Các vấn đề thường gặp
Pitfalls & Solutions
05 — Xu hướng tương lai · 2025+
Fine-tuning truyền thống đang biến mất.
Thay vì fine-tune hàng triệu params tốn kém, Foundation Models mở ra kỷ nguyên Prompt Engineering: chỉ cần thiết kế câu prompts (text/visual) để hướng dẫn model làm task mới — không cần training.

Contrastive Language-Image Pretraining (OpenAI). Embedding text+image chung 1 space. Zero-shot classification: mô tả class bằng text prompt, so similarity cosine với image embedding — không cần label.
Segment Anything Model (Meta). Huấn luyện trên SA-1B: 11M ảnh, 1 tỷ masks. Promptable: click / bbox / text → mask tức thì. Thay thế Mask R-CNN / U-Net mà không cần fine-tune.
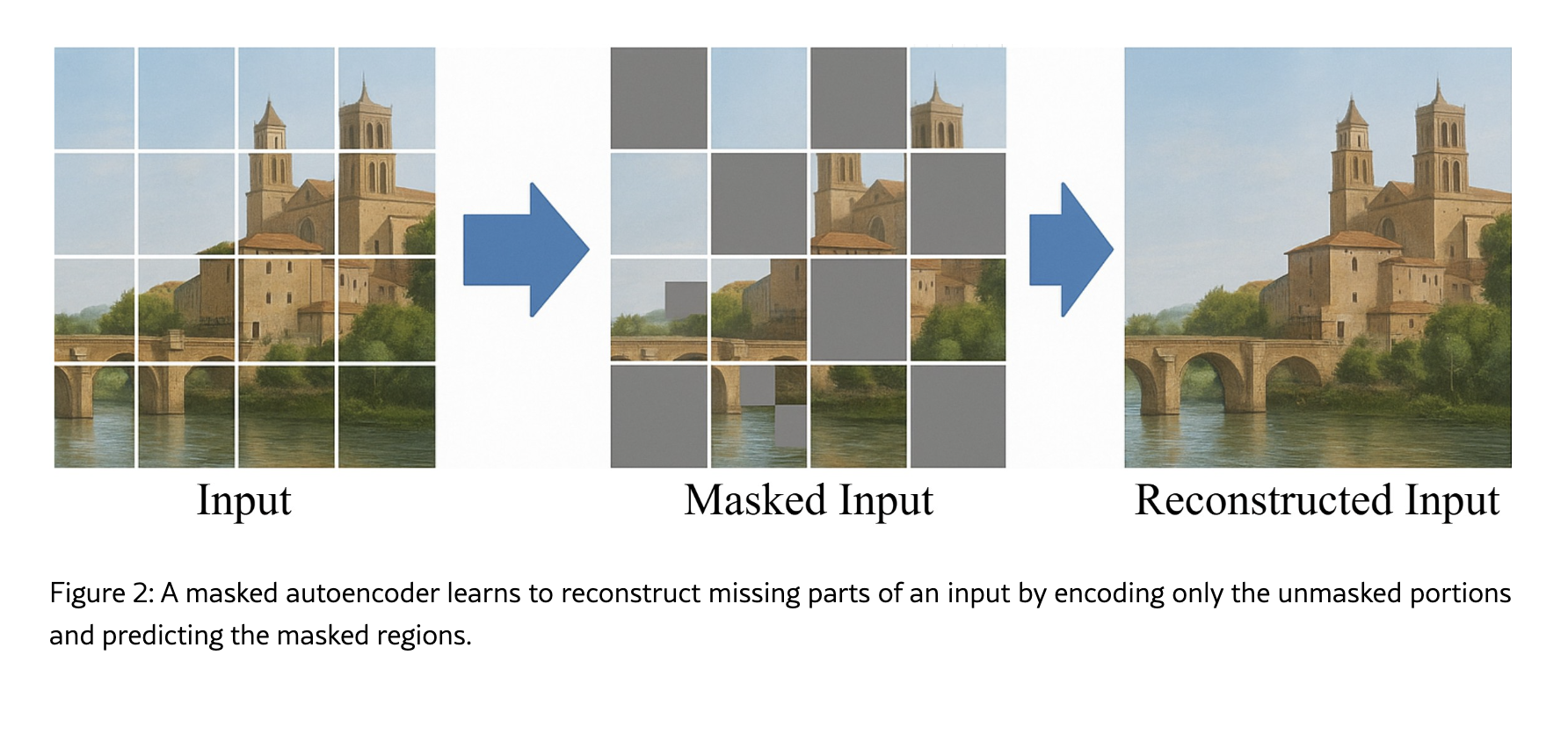
Masked Autoencoders (He et al.). Mask 75% patches ngẫu nhiên → ViT encoder-decoder reconstruct pixel. Học spatial relationships tinh vi. Representations ổn định khi fine-tune downstream tasks.
Distillation with No Labels v2 (Meta AI). Teacher-Student self-distillation + Sinkhorn normalization + KoLeo regularizer. Frozen features đánh bại supervised fine-tuning trên nhiều dense prediction tasks — 2025 SOTA.
2026 Trend: Kết hợp frozen DINOv2 features + SAM segmentation + CLIP zero-shot — pipeline "Transfer Learning không cần training" — biến mọi tác vụ vision thành bài toán Prompt Engineering thuần tuý.